

デー太くんと学ぶ #04「データの信頼性とデータクレンジング」

前回、販売/購買データ分析システムにおけるデータの収集について学んだデー太くん。
今回は次のステップである"整える"について学んでいくようです。
はじめに
デー太くん:みなさん、お久しぶりです、デー太です!
新年度や新学期など、新しいことが始まる季節になりましたね。
この春から新生活を始められた方も多いのではないかと思います。
ですが、みなさんお気づきでしょうか?
実は、このシリーズも今回から新しくなったところがあります!
どこだか分かりますか?
もちろん主役である僕は今後も健在ですよ!
羽留(はねる)先輩:私もちゃんといるよ~。
デー太くん:羽留先輩、今回もよろしくお願いします!
ということで、お送りするメンバーはこれまで通りですが、今回からなんと、記事やマガジンのトップ画像が新しくなりました~!
羽留先輩:わ~!(パチパチパチ)
デー太くん:みなさんちゃんとお気づきいただけましたか?
記事の内容などはこれまで通り変わりなく続けていきますので、今後もよろしくお願いします!
ということで、今日もさっそく本題に入っていきましょうか。
羽留先輩:今日は何を紹介していくのかな?
デー太くん:前回は集める・整える・分析する・見せるの4ステップの中の"集める"についてフォーカスしたので、今回は次の"整える"についてフォーカスしていきたいです!
羽留先輩:"整える"ということは、データクレンジングのところだね。
データクレンジングはデータを分析するための前処理としてとても大切なところだから、今回もしっかり学んでいこうね!
デー太くん:はい、よろしくお願いします!
前回の"集める"についても、まだご覧になられていない方はぜひこちらからチェックしてみてください!
データクレンジングとは
羽留先輩:まず初めに、データクレンジングと聞いてデー太くんはどんなイメージを持つかな?
デー太くん:クレンジングということは、"きれいにする"ということですよね。
たしか以前パネルシステム全体の流れを教えていただいたときに、"整える"の工程では"データを実情に近づける"と伺ったと思うのですが、それが"きれいにする"ということでしょうか?
羽留先輩:さすがデー太くん、よく覚えているね!
ここで言う"きれい"というのは、"異常のない"といった意味だと思ってくれれば大丈夫だよ。
デー太くん:そうなんですね!
であれば、データクレンジングは、集めたデータを異常のない状態に整える、といった感じでしょうか?
羽留先輩:その通り!
販売/購買データ分析システムでは、たくさんデータを集めているぶん、異常なデータが入ってきてしまう可能性もあるんだ。
だからこそ、データクレンジングでデータに異常がないか確認し、異常なデータがあれば修正や除外をして、データ全体の信頼性を維持することが大切なんだよ!
データクレンジングの必要性
デー太くん:なるほど、データクレンジングによってデータの信頼性が守られているんですね!
でも、異常なデータと一言で言っても、さまざまなパターンがありそうですよね。
羽留先輩:そうだね。
データの異常にはさまざまなパターンがあるし、異常の内容によっても必要な対応は変わってくるんだ。
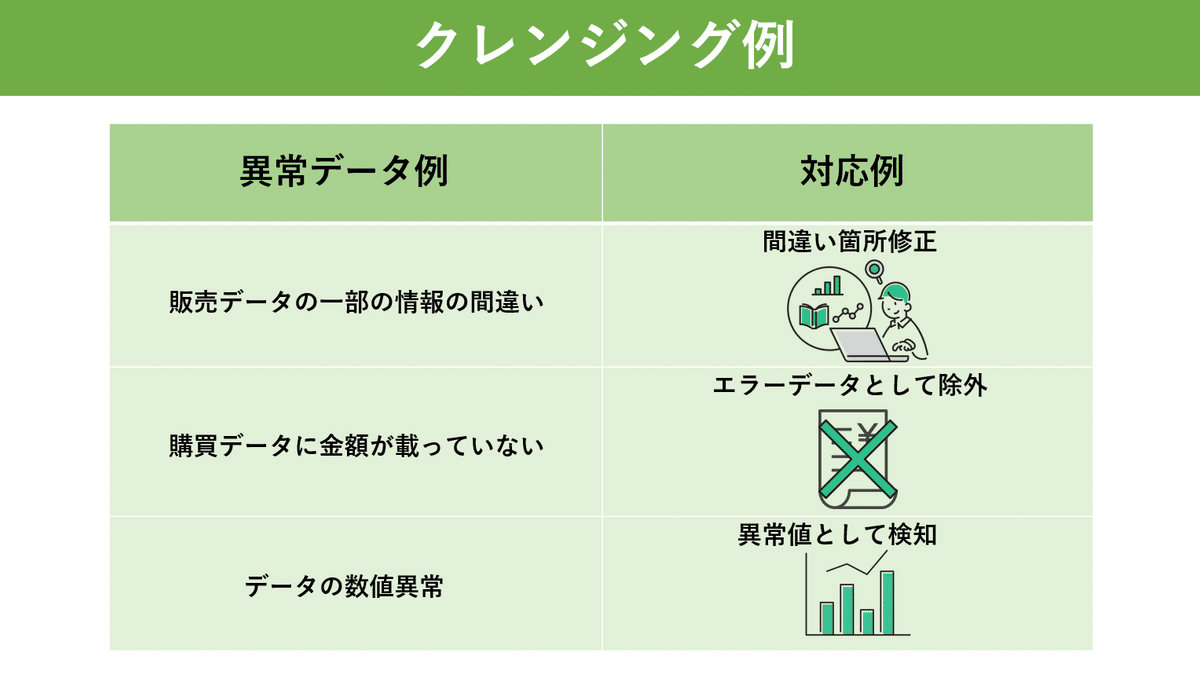
たとえば、異常のパターンとしては
販売データの一部の情報が間違っていた
購買データに金額が載っていなかった
ある店舗でのある商品の販売数が過去のデータや他の店舗のデータと比べて異常なほど多くなった
などが挙げられるね。
そして、これらはそれぞれ必要な対応も違ってくるんだ。
デー太くん:やっぱり異常の内容はさまざまあるんですね。
しかも、内容によって対応方法を変えないといけないなんて、思っていた以上にデータクレンジングは複雑な作業なんですね。
羽留先輩:そうなんだよね~。
"データをきれいにする"、と一言で言っても、実際の作業としてはけっこう
いろいろあるんだ。
さっきのたとえで出したものだと、まず1つ目の、販売データの一部の情報が間違っていた、というようなパターンでは、こちら側で持っている情報を元にデータの間違い箇所を修正することで、正しいデータとして販売/購買データ分析システムへ取り込むことができるんだ。
でも、2つ目の、購買データに金額が載っていなかった、というようなパターンでは、モニターさんが実際にいくらで商品を購入したかはこちらでは判断のしようがないよね。
だからこういった場合は、仕方がないからエラーデータとして除外するしかないんだ。
そして3つ目の、ある店舗でのある商品の販売数が過去のデータや他の店舗のデータと比べて異常なほど多くなった、というようなパターン。
このパターンは、他の2つとは違って、送られてきたデータ自体は特に間違っているわけではないんだ。
なんだけど、データ全体として見たときには、明らかに異常な数値になってしまっていることがあるんだよね。
たとえば、先週まで100個しか売れてなかったものが、突然今週10,000個も売れたら明らかにおかしいよね?

デー太くん:そうですね、それは明らかにおかしいと思います。
そういえば、この前近所のコンビニで誤発注でエナドリを大量入荷しちゃったらしく激安セールをしてたんですが、そういった場合にはたしかに、販売データとしては間違っていなくてもデータ全体としては異常、ということが起こりそうですね。
それに、そういった場合のデータは販売個数や金額が通常とは異なりそうなので、データを分析した際にも悪影響が出てしまいそうですよね。
羽留先輩:まさにその通りなんだよ!
こういった異常なデータは、分析のときに他のデータと同じように扱ってしまうと、誤った分析結果が出てしまう原因になりかねないんだよね。
だから、データクレンジングの段階でそういったデータを見つけておく必要があるんだ。
データの信頼性を支えるクレンジング技術
デー太くん:単純にデータが間違っているというだけでなく、他のデータと見比べたときに異常なものも見つけないといけないんですね。
でも、これらすべてを見落としなくチェックしていくのはかなり難しいんじゃないですかね?
羽留先輩:だからこそ、データクレンジングでは独自のロジックを使ったシステムによるチェックと人の目でのチェックによるダブルチェックを行っているんだ!
しかも、システムによるチェックでは機械学習も導入されていて、日々チェック体制も強化されていっているんだよ!

デー太くん:そうなんですね!
それなら安心してデータを使えますね!
羽留先輩:データを扱う上で、大元のデータを整えるデータクレンジングは無くてはならない作業だからね。
ここにもしっかりとインテージグループの長年蓄積された技術が生かされているんだ!
デー太くん:データクレンジングの奥深さと大切さがよく分かりました!
今日もありがとうございました!
今日の"ここがすごい‼"
・データクレンジングによって、データ全体の信頼性が守られている!
・独自のロジックを使ったシステムによるチェックと人の目でのチェックによるダブルチェックを行い、データに異常がないか厳しくチェックしている!
・システムによるチェックでは機械学習も導入されていて、日々チェック体制も強化されている!
デー太くんと学ぶシリーズはこちら!